Origin, site, eTLD, eTLD+1, public suffix, PSL. What are they?
We call it pages, domains, servers, websites, internets and we hope the other party will understand. Maybe, maybe not, but that can always be cleared with the additional “wait, a server, don't you mean a website?” You can't just ask those questions when reading various specifications and technical documents, so they try to call things by their correct names and in a consistent manner. And they do it so well that terms like origin, site, same origin, same site, eTLD and public suffix are normally not even translated to other languages, because then nobody would understand it. And how does the attractiveness of subdomains relate to this?
I've realized I'm using some of these terms in almost every article or talk, and rather than explain it every time (and each time simplified in a different way), I've decided to make it into this article that I can link to. Almost all of it could be expressed with the following picture:
A picture is worth a thousand words, but this blog post is worth two thousand two hundred and twelve
We won't go into the secrets of URL and all its parts, it would take us a hundred years. We'll just explain what is in the title, because the browser sets certain boundaries based on that.
Imagine a simple URL, for example:
https://www.example.com/foo/bar
Domain
This may be more of a refresher, but it will come in handy later. The domain in the URL above is www.example.com and has several levels:
- The top-level domain (TLD) is
com - The second-level domain (2LD) is
example.com - The third-level (3LD) is
www.example.com - And so on
Instead of a domain, it can also be an IP address, but for simplicity we'll stick with domains.
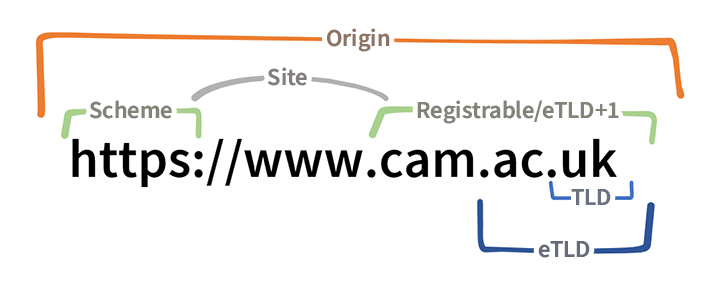
Registrable domain
A registrable domain is that part of a domain that you can register or lease either from a domain registrar or from another entity that offers e.g. blogs on subdomains. If we ignore any further delegation, all subdomains under the registrable, including it, belong to the same organization.
You could also say that a registrable domain is what you type in the registration form. If you want to have a website at www.michalspacek.com, you also register only michalspacek.com. However, a registrable domain is not always the same as a second-level domain.
This is the case, for example, in the United Kingdom, where universities and other academic institutions can register domains that identically end in ac.uk (ac as academia) and differ only in the third-level domain. Examples include the two rival universities of Oxford (ox.ac.uk) and Cambridge (cam.ac.uk). Other common domains are co.uk (for commercial entities) and net.uk (internet service providers), with almost 20 in total.
It's the same in many other countries, subdomains such as ….gov.something for various government organizations can often be seen (for example ….gov.cz in the Czech Republic). Similarly for domains of various storages such as ….s3.amazonaws.com for Amazon S3 or domains such as ….blogspot.com for Google's Blogger.
| Domain | Registrable domain |
|---|---|
example.com | example.com |
www.example.com | example.com |
foo.bar.example.com | example.com |
ox.ac.uk | ox.ac.uk |
www.ox.ac.uk | ox.ac.uk |
talks.ox.ac.uk | ox.ac.uk |
blogs.law.ox.ac.uk | ox.ac.uk |
portal.gov.cz | portal.gov.cz |
drozd.mzv.gov.cz | mzv.gov.cz |
my.foo.s3.amazonaws.com | foo.s3.amazonaws.com |
foo.blogspot.com | foo.blogspot.com |
www.foo.blogspot.com | foo.blogspot.com |
A registrable domain is sometimes colloquially called “naked domain”, “base domain”, “root domain” or “apex domain”. These expressions are probably never translated into other languages, because under some of these expressions, many would certainly imagine something completely different.
Registrable domain is defined in the URL Standard.
Effective top-level domain (eTLD) and eTLD+1
An effective top-level domain, abbreviated eTLD, is a domain one level above a registrable domain. eTLD is a domain under which other domains are registered, usually by different owners. Often the eTLD is equal to the TLD itself, but in many cases it is not. Looking at a domain unfortunately doesn't allow us to simply find its effective top-level or registrable domain algorithmically or with a regular expression, but there is a list of eTLDs that we (or a machine) can look at, see below.
An effective top-level domain plus one or eTLD+1 is the same as a registrable domain.
| Domain | eTLD |
|---|---|
example.com | com |
www.example.com | com |
foo.bar.example.com | com |
ox.ac.uk | ac.uk |
www.ox.ac.uk | ac.uk |
talks.ox.ac.uk | ac.uk |
blogs.law.ox.ac.uk | ac.uk |
portal.gov.cz | gov.cz |
drozd.mzv.gov.cz | gov.cz |
foo.blogspot.com | blogspot.com |
www.foo.blogspot.com | blogspot.com |
eTLD cannot be registrable, in other words: a registrable domain part of eTLD is null.
Public suffix list (PSL)
PSL is a list of effective top-level domains, eTLDs, but here they're called “public suffixes”, because they are basically suffixes of publicly registrable domains. The file is available from publicsuffix.org (direct link) and is updated using pull requests on GitHub.
The part of the code that tries to find the eTLD for e.g. the Australian domain www.schools.vic.gov.au has to look in that list and see if:
- Is
aua public suffix? It is, similar to other country code top-level domains (ccTLD). - Is
gov.aua public suffix? Yes. - Is
vic.gov.aua public suffix? Also yes. - Is
schools.vic.gov.aua public suffix? No, it isn't. - Is
www.schools.vic.gov.aua public suffix? Also not.
So the result is that the effective TLD (eTLD) is vic.gov.au, the registrable domain and at the same time the eTLD+1 is schools.vic.gov.au.
It's actually a bit more complicated, because the list also includes entries with * and !, like e.g. *.ck ([anything].ck is an eTLD) and !www.ck (… except www.ck), but we'll leave that out for simplicity.
It is also necessary to go through the whole domain, it is not enough to stop at the first “no”, because it could easily happen that the “public suffix” is encountered somewhere later: the eTLD of the domain files.s3.amazonaws.com is s3.amazonaws.com, because like com, s3.amazonaws.com is also a public suffix, but just amazonaws.com is not.
Browsers use public suffix list mostly to restrict cookies from being set to apply to all domains with the suffix .co.uk etc. Firefox also uses the list to highlight domains in the address bar.

Highlighting eTLD+1 in Firefox 119

The same domain loaded in Chrome 119
The public suffix list is also used by certification authorities when issuing wildcard certificates for HTTPS, because they are not allowed to issue a certificate for e.g. *.co.uk. And you can use the list too, for example to warn your users that “you probably don't want to do this with this domain”, but ideally for nothing else. Libraries exist for many languages. Personally I have experience with the PHP Domain Parser, which can also use a locally cached list.
Origin
The term origin refers to the part of the URL that contains the protocol (more precisely, the scheme), the domain and the port.
| URL | Origin |
|---|---|
https://www.example.com/foo | https://www.example.com |
https://www.example.com:303/foo | https://www.example.com:303 |
Note that origin does not end with a slash, which already belongs to the path part /foo.
Same origin
By the term same-origin policy we mean several different restrictions that allow two things to somehow work together if and only if they have a “same origin” relationship, in simple terms if they have the same origins.
Same-origin policy is also used e.g. to restrict JavaScript running in an iframe (typically as part of an advertisement) so that it cannot steal, I mean read from the parent document using for example window.parent.document.getElementById('username'), unless the iframe and the parent document have the same origin. In such case it's not even possible the other way around, the parent document cannot access the iframe contents (with for example document.getElementById('iframe').contentWindow.document.getElementById('username')).
✔️
https://example.com/foo&https://example.com/barare “same origin”https://foo.bar.baz.test/foo&https://foo.bar.baz.test/barare “same origin”, the domain doesn't matter, it can be.comor.anything, it just has to be the same in both cases
❌
https://example.com/foo&https://www.example.com/bararen't “same origin” (example.comandwww.example.comare not the same domain)https://example.com/foo&http://example.com/bararen't “same origin” (httpsandhttpare not the same protocols)https://example.com:4431/foo&https://example.com:4432/bararen't “same origin” (the ports are different)
For more information about origin and same origin in slightly more formal language, see the HTML specification.
Site
The term “site” is often used to refer to an entire website, server, or something like that, but we're here to go deeper. Site means a subset of a URL, which includes a protocol (schema) and a registrable domain.
| URL | Site |
|---|---|
https://www.example.com/foo/bar | https & example.com |
https://neco.nek.de.example.com/foo/bar | https & example.com |
http://www.ox.ac.uk/ | http & ox.ac.uk |
https://staff.admin.ox.ac.uk/ | https & ox.ac.uk |
https://www.cam.ac.uk/ | https & cam.ac.uk |
https://my.foo.s3.amazonaws.com/ | https & foo.s3.amazonaws.com |
https://foo.blogspot.com.au/ | https & foo.blogspot.com.au |
https://www.foo.blogspot.com.au/ | https & foo.blogspot.com.au |
Same site
Two URLs or two origins are “same site” if their sites are equal, i.e. if they have the same protocols (schemes) and registerable domains. Unlike same origin, neither the port nor the entire domain matters in this case.
✔️
https://example.com/foo&https://example.com/barare “same site” (and “same origin”), their site ishttpsandexample.comhttps://example.com/foo&https://foo.bar.example.com/barare “same site” (but not “same origin”), site is identicallyhttpsandexample.comhttps://www.example.com/foo&https://foo.bar.example.com/barare “same site”, site of both ishttpsandexample.comhttps://www.cam.ac.uk/&https://www.cambridgestudents.cam.ac.uk/are “same site”, their site ishttpsandcam.ac.uk
❌
https://example.com/foo&http://example.com/barhave different protocols and they are not “same site” even though their registrable domain is the samehttps://www.ox.ac.uk/&https://www.cam.ac.uk/are not “same site”, they have different registrable domainsox.ac.ukandcam.ac.ukhttps://example.com/&https://example.net/are not “same site”, they have different registrable domainsexample.comandexample.nethttps://example.com./&https://example.com/are not “same site”, they have different registrable domainsexample.com.andexample.com, that dot at the end is significant
“Same site” checks are used, for example, by the browser to restrict cookies, which it either sends in the request or not, depending on whether you clicked the link on the same site as the site of the target address, according to the setting of the SameSite cookie attribute.
The terms site and same site are described in more detail in the HTML specification. Also worth noting is that there is a “same site” comparison without a scheme (schemelessly same site), which compares only registrable domains. This was once used for cookies, but then switched to “schemeful same site” matching, in which the scheme also plays a role, which we now call simply “same site”.
Cross-origin and cross-site requests
Requests that originate on one origin but load something from another origin are called cross-origin requests, basically the opposite of “same origin”.
Similarly, cross-site requests, the opposite of “same site”, were created on one site but load something from another site. Just beware that somewhere, e.g., in the names of attacks like Cross-Site Scripting (XSS) or Cross-Site Request Forgery (CSRF), “site” is used in the general sense, not in the “schema + registrable domain” sense explained above.
Prefer same origin
The concept of site and public suffixes and their list requires some manual work to match the actual reality as much as possible, and it reminds me of that random person from Nebraska. If you were writing a specification, it would be more appropriate to use origin and same origin, otherwise the definition of site may differ from browser to browser, because each may use a different version of PSL.
The public suffix list is maintained by Mozilla, the maker of Firefox, so the “big” browsers and the “smaller” ones built on top of them will probably be fine. But it's still a good idea to consider whether you want to base the security of your work on whether someone adds a line to a file and whether someone else downloads that file in time. You don't.
Using “same site” also makes subdomains more attractive to attackers. Subdomain takeover is a real attack by which attackers can bypass various restrictions using “same site” matching. For all this, they may even just need a forgotten subdomain that is not used for anything.
Just prefer same origin.
Recommended reading
- The great SameSite confusion by Julien Cretel

Michal Špaček
I build web applications and I'm into web application security. I like to speak about secure development. My mission is to teach web developers how to build secure and fast web applications and why.